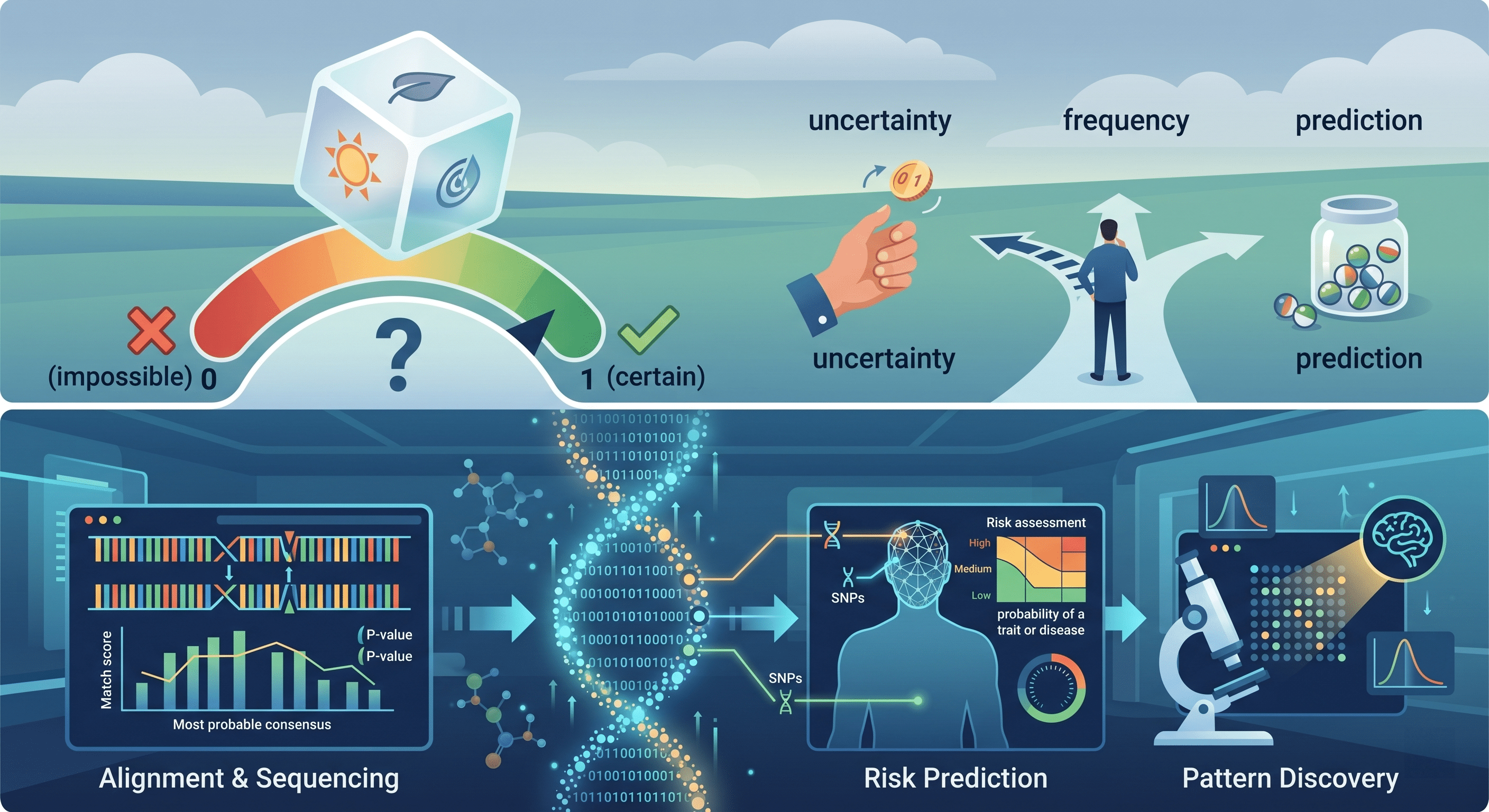
La **bioinformática** ha revolucionado el estudio de la biología, facilitando la comprensión de estructuras biológicas complejas y procesos biomoleculares fundamentales. Uno de los aspectos más fascinantes de esta disciplina es el análisis de similitud, que permite a los investigadores identificar similitudes y diferencias en secuencias de ADN, ARN o proteínas. Esta técnica es esencial para descifrar la función de un gen, clasificar organismos e incluso predecir la aparición de enfermedades, lo que pone de manifiesto la importancia de comprender sus fundamentos y aplicaciones.
En este artículo, exploraremos en profundidad el **análisis de similitud en bioinformática**. Abordaremos los diferentes métodos y algoritmos utilizados, desde aquellos más simples hasta los más sofisticados, y presentaremos casos prácticos que ilustran su utilidad en la investigación científica. Además, discutiremos la interpretación de los resultados obtenidos y cómo estos pueden influir en nuestros conocimientos sobre la biología y la medicina. A medida que te adentres en este contenido, adquirirás una visión integral que te permitirá apreciar la relevancia del análisis de similitud en un contexto más amplio.
¿Qué es el análisis de similitud en bioinformática?
El **análisis de similitud** en bioinformática se refiere al proceso mediante el cual se comparan secuencias biológicas (como ADN, ARN o proteínas) para evaluar su relación. Esto puede incluir la identificación de secuencias que comparten un cierto grado de homología, así como la búsqueda de patrones conservados que pueden tener implicaciones funcionales. Los métodos más comunes para llevar a cabo este tipo de análisis incluyen la alineación de secuencias y el uso de bases de datos génomicas que permiten la búsqueda de homologías.
La importancia del análisis de similitud radica en que, al comparar secuencias, los científicos pueden inferir información útil sobre la estructura y función de un gen o proteína desconocida al encontrarlo en un organismo conocido. Este enfoque no solo permite identificar funciones biológicas, sino que también ayuda a elucidarlo en un contexto evolutivo, revelando cómo han cambiado las secuencias a lo largo del tiempo. Por esta razón, el análisis de similitud es una herramienta fundamental en la biología molecular y genética.
Métodos de análisis de similitud
Los enfoques más utilizados para el análisis de similitud se basan en la alineación de secuencias. Existen varios algoritmos que pueden clasificarse en dos tipos principales: **alineación global** y **alineación local**. La alineación global busca encontrar la mejor coincidencia posible entre dos secuencias a través de todo su largo, mientras que la alineación local se centra en encontrar coincidencias óptimas en segmentos de las secuencias que pueden no ser congruentes en la totalidad.
Un ejemplo clásico de un algoritmo de alineación global es el algoritmo de **Needleman-Wunsch**, que utiliza programación dinámica para crear una matriz que compara las posiciones de las secuencias. Esto permite optimizar el puntaje de alineación, considerando las similitudes y diferencias. Por otro lado, el algoritmo de **Smith-Waterman** es representativo de la alineación local y opera mediante un proceso similar, aunque se enfoca solo en subsecuencias que tienen mayor grado de coincidencia.
Además de estos algoritmos, las herramientas computacionales como BLAST (Basic Local Alignment Search Tool) han ganado popularidad en la comunidad científica debido a su capacidad para buscar rápidamente secuencias similares en grandes bases de datos. Esta herramienta permite a los investigadores acceder a información valiosa de manera eficiente y es fundamental en el análisis de datos genómicos masivos generados por tecnologías de secuenciación de nueva generación.
Interpretación de resultados
Una parte esencial del análisis de similitud es la correcta interpretación de los resultados. Cuando dos secuencias muestran un alto grado de coincidencia, esto puede indicar que comparten una función biosintética o evolutiva común. Sin embargo, es imprescindible tener en cuenta el hecho de que las similitudes pueden ser conservativas, significando que las secuencias pueden haber evolucionado de manera independiente a lo largo del tiempo y aún así presentar homología debido a una presión de selección similar. Por lo tanto, es importante considerar el contexto biológico en el que se realiza y cómo este puede influir en la puntuación de alineación que se obtiene.
El uso de **estadísticas** en la interpretación de resultados también es crucial. Los valores de E, que indican la expectativa de encontrar coincidencias aleatorias, juegan un papel importante en la evaluación de la significancia de un alineamiento. Un pequeño valor de E sugiere que el alineamiento es significativo y, por lo tanto, podría tener implicaciones funcionales y evolutivas importantes. Sin embargo, hay que recordar que una coincidencia alta en el alineamiento no siempre implica función, y el análisis debe integrarse con información biológica adicional para ofrecer conclusiones más sólidas.
Aplicaciones del análisis de similitud en investigación
El análisis de similitud tiene múltiples aplicaciones en diferentes áreas de la **bioinformática** y la biología en general. Un área primordial es la **filogenética**, donde los científicos utilizan comparaciones de secuencias para inferir la relación evolutiva entre especies. A través de árboles filogenéticos construidos a partir de secuencias similares, se puede trazar la evolución y diversidad genética de los organismos. Esto no solo contribuye al entendimiento de la historia de vidas pasadas, sino que también puede ser útil en estudios sobre la evolución de enfermedades o la resistencia a fármacos.
Además, el análisis de similitud es fundamental en la identificación de **marcadores genéticos** relacionados con enfermedades. Estudios que comparan genomas de individuos sanos y afectados pueden revelar variantes asociadas a trastornos específicos, lo que permite avanzar en la comprensión de mecanismos moleculares y potencialmente desarrollar tratamientos personalizados. La identificación de homologías también es pilar en la predicción de funciones de proteínas, permitiendo a los investigadores inferir el rol de proteínas desconocidas por su similitud a proteínas previamente caracterizadas.
Desafíos en el análisis de similitud
A pesar de su utilidad, el análisis de similitud no está exento de desafíos. La gran cantidad de datos generados por las técnicas modernas de secuenciación puede dificultar el manejo y análisis de información relevante en un tiempo razonable. Las bases de datos requieren mantenimiento y actualización constante, y a veces, la calidad de los datos puede ser variable, lo que afecta los resultados obtenidos. Además, el alineamiento de secuencias de proteínas requiere a menudo la consideración de su estructura tridimensional, lo que añade complejidad al análisis.
Otro desafío relevante es el manejo de secuencias repetitivas, que pueden dar lugar a alineamientos ambiguos que dificultan llevar a cabo interpretaciones claras. Para enfrentar estos desafíos, los investigadores deben emplear herramientas robustas y aplicar enfoques multimodales, que integren información genómica, transcriptómica y proteómica para obtener una visión más holística de la biología de los sistemas investigados.
Perspectivas futuras
El campo del análisis de similitud en bioinformática está en constante evolución. Con el advenimiento de tecnologías como la **inteligencia artificial** y el **aprendizaje automático**, los algoritmos para el análisis de similitud están mejorando y evolucionando, permitiendo realizar comparaciones más eficientes y precisas. Esto no solo acelerará el ritmo de los descubrimientos en biología, sino que también permitirá abordar preguntas más complejas relacionadas con la evolución, la función y la regulación genética.
Además, la integración de datos de múltiples omicas (genómica, transcriptómica y proteómica) seguirá abriendo nuevos caminos para entender los sistemas biológicos desde una perspectiva más integradora. La combinación de estos enfoques apunta a descubrir, por ejemplo, interacciones entre genes y proteínas que antes no se podían identificar, lo que permitirá una comprensión más detallada de las funciones biológicas.
Conclusión
El **análisis de similitud en bioinformática** es una herramienta fundamental para explorar el vasto paisaje de la biología. A través de diversos métodos y técnicas, los investigadores son capaces de identificar relaciones evolutivas, inferir funciones a partir de datos genómicos e incluso descubrir nuevos marcadores de enfermedades. A pesar de los desafíos que enfrenta el análisis de similitud, su evolución continua junto con la tecnología promete avanzar nuestra comprensión de los mecanismos fundamentales de la vida. Con el desarrollo de nuevas metodologías y recursos, el futuro del análisis de similitud será, sin duda, emocionante y lleno de potenciales descubrimientos que transformarán el campo de la bioinformática y sus aplicaciones en la medicina y la biología.